초보자라면 HDFS 헷갈리는 기본 개념 정리 (3) - Tez
이제 상황에 맞게 impala나 hive 쿼리를 나눠서 던질 수 있게 되었고, table upsert 및 delete가 필요하다면 kudu 테이블을 사용할 수도 있게 되었다. 하지만 hive table 을 사용하다보면 Tez 라는 단어를 보게된다.
Hive에 쿼리를 날리고 로그를 들여다보면 Tez Session이 열린다는 이야기가 보이고, Tez UI 에서 MapReduce 작업의 현황을 확인할 수도 있다. Tez가 뭐길래 Hive table을 쓸 때마다 언급이 되는건지 궁금해진다.
Apache Tez
Apache Tez는 빅데이터 분석을 위한 유연하고 강력한 데이터 처리 엔진이다.
Apache Tez의 주요 목표는 MapReduce 모델의 제한성을 극복하고, 하둡 생태계의 다양한 도구들과 잘 통합되도록 하는 것이다. MapReduce는 하둡의 핵심 데이터 처리 모델이지만, 복잡하고 반복적인 데이터 처리 작업에는 비효율적일 수 있기 때문이다.
YARN 기반으로 동작하며, 데이터 처리를 위한 DAG(Directed Acyclic Graph)라는 모델을 사용하여 여러 단계의 작업을 병렬로 처리하고 데이터의 중간 결과를 메모리에 저장하여 처리 속도를 높인다.
MapReduce VS Tez
여기 까지 읽으면 왜 그 유명한 MapReduce 프레임워크를 대체하기 위한 수단으로 나온건지 궁금해진다.
MapReduce 프레임워크는 병렬 처리를 통해 대량의 데이터를 빠르게 처리할 수 있지만, 일부 작업에 대해선 복잡하고 비효율적일 수 있다.
예를 들어 MapReduce는 각 작업이 독립적이어야 한다. 이는 복잡한 데이터 처리 워크플로우에서 여러 개의 MapReduce 작업을 연결해야 하는 경우에 문제가 될 수 있다. 이러한 복잡한 워크플로우를 처리하려면 각 맵리듀스 작업이 완료될 때마다 중간 결과를 디스크에 쓰고, 다음 작업이 그 결과를 다시 읽어야 한다. 이는 I/O 비용이 크고, 전반적인 처리 속도를 늦출 수 있다.
그 예시는 이미 많이 알려져 있는데, word count, Collating, Sorting 등은 적절한 반면 iterative한 처리(머신러닝), cross-correlation 등 두개의 일이 동시에 일어나는 횟수를 세는 작업에서는 효율적이지 않다.
그에비해 Tez는 데이터 처리 워크플로우를 DAG 모델로 표현하며, 이를 통해 여러 단계의 작업을 더 효율적으로 연결하고, 병렬로 실행할 수 있다. 또한 Tez는 메모리에서 중간 결과를 관리하고, MapReduce보다 더 세밀한 리소스 관리를 제공함으로써, 더 효율적인 데이터 처리를 가능하게 한다. 메모리를 사용하기 때문에 MapReduce에서는 발생하는 중간 데이터의 디스크 I/O를 크게 줄일 수 있다.
또한, Tez의 DAG 모델로 표현된 워크플로우는 고정된 Map -> Reduce 형태가 아니기 때문에 더 유연하게 워크플로우를 구성할 수 있다. 아래에서 더 자세히 다뤄보자.
그럼 Tez에서는 MapReduce를 사용하지 않나?
Tez UI 에서는 Map / Reduce 각각의 작업 현황을 볼 수 있는데?
반쯤은 맞고 반쯤은 틀리다. Tez는 Map Reduce를 완전히 배제하고 있진 않다.
Map Reduce
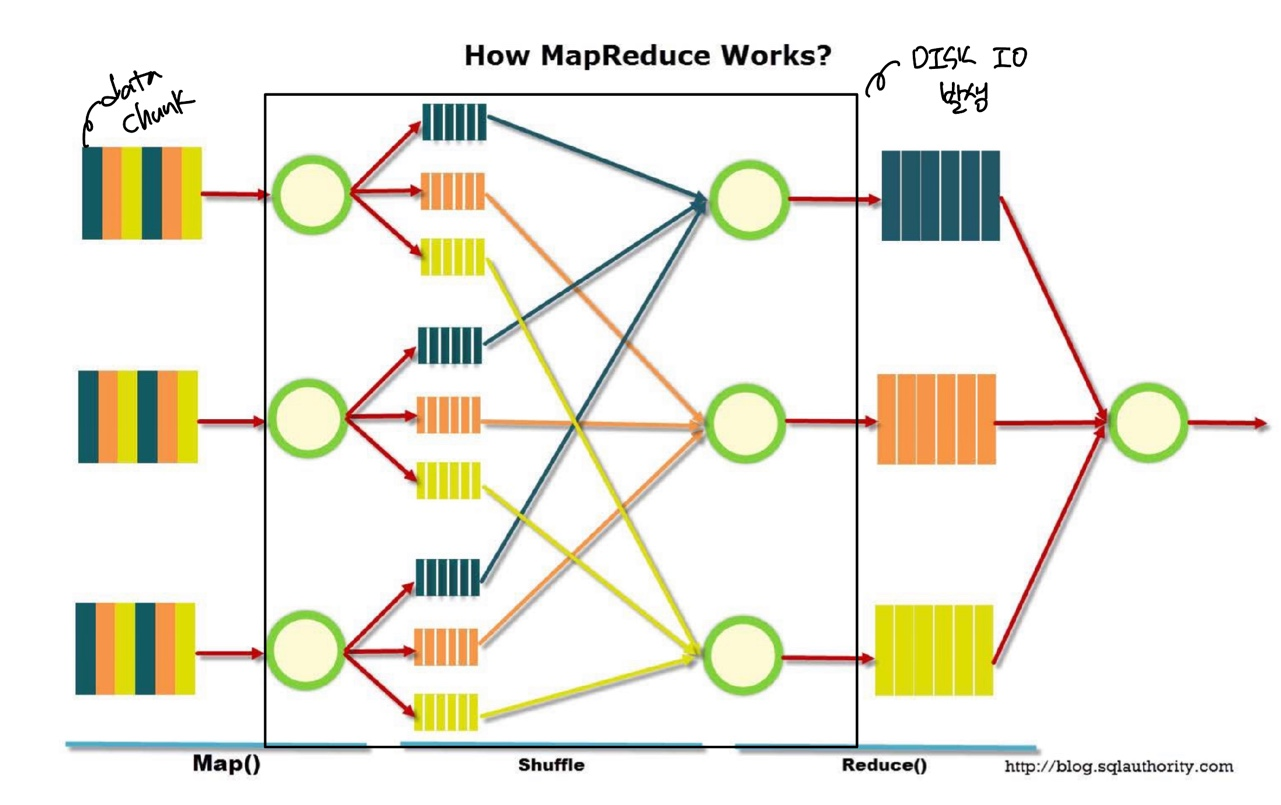
네모로 둘러쌓인 부분에서 처리 결과를 매번 Disk에 저장한다. 또한 고정된 두 단계인 Map과 Reduce로 이루어지며 모든 작업이 완전히 독립적이다. Map 작업이 끝나야지만 Reduce 작업을 실행할 수 있고, 두 작업 중 하나가 생략될 수 없다.
Tez
Defines a vertex in the DAG. It represents the application logic that processes and transforms the input data to create the output data. The vertex represents the template from which tasks are created to execute the application in parallel across a distributed execution environment.
출처 : https://tez.apache.org/releases/0.6.0/tez-api-javadocs/org/apache/tez/dag/api/Vertex.html
Tez는 작업의 흐름을 DAG로 표현하기 때문에 Map, Reduce로 작업이 고정되어 있지 않다. 이때, 더 일반화된 "Vertex"라는 개념을 사용한다. Vertex는 데이터 처리 작업의 단위이고, Edge는 작업들 간의 데이터 흐름을 나타낸다. Map Reduce 프레임워크에 적절하지 않은 병렬 처리가 필요한 작업이라면 Vertex로 작업을 분리하여 병렬로 처리하게끔 DAG를 구성한다. 이 과정에서 각각의 Vertex와 Edge를 DAG로 관리하고, 중간 처리 결과는 메모리에 저장한다. 이 과정에서 디스크 I/O가 크게 준다는 것이다. 다만, vertex의 종류는 Map, Reduce이고 MapReduce 프레임워크와 다른 점은 Map 다음에 꼭 Reduce가 나올 필요는 없다는 점이다. Reduce가 Reduce에게 데이터를 넘겨줄 수 있고, Map이 Map에게 데이터를 넘길 수 있다.
MapReduce에 필수적으로 들어가는 Split과 Shuffle 과정도 마찬가지이다. MapReduce의 Split은 Tez에서는 input 작업으로 대체되고 이 과정에서 데이터를 처리하기 위한 적합한 chunk 로 나눈다.
Shuffle은 MapReduce에서는 Map의 출력을 Reduce로 전달하는 중요한 과정인데 Tez에서는 Intermediate 단계로서 각 작업의 출력을 다른 vertex로 전달하는 역할을 말한다. 이러한 예시들에서 Tez가 더 유연하게 데이터를 처리하는 걸 볼 수 있다.
그리고 Tez는 작업을 실행하기 이전에 필요에 따라 작업 간의 종속성을 정의하고, 병렬로 수행될 작업 그룹을 동적으로 조정할 수 있다. 이를 통해 실행 계획을 최적화 하고 자원을 효율적으로 활용한다.
결론적으로 Tez가 더 높은 성능과 유연성을 제공할 수 있다.
만능 Tez!
Tez는 정말 만능일까? 대체적으로는 Tez가 빠르다고 알려져 있지만, 역시나.. ALWAYS는 없다.
- Tez는 간단한 작업도 워크플로우 최적화 과정을 거치기 때문에 간단한 MapReduce의 경우에는 MapReduce가 빠를 수도 있다.
- 중간 결과를 메모리에 저장하기 때문에 중간 결과값이 클 경우에는 메모리가 부족할 수도 있다.
- 이럴 경우 set hive.tez.container.size=숫자 로 HiveQL을 날려서 메모리 사이즈를 임시로 늘려 해결할 수 있다.
이러한 단점을 딛고도 대체로 MapReduce보다 높은 성능을 제공하기 때문에 요즘에는 보통 Hive on Tez를 더 많이 보게되는 것 같다.