[17일차] RNN 본격 탐구 - 코드위주
진짜 너무 깔끔하다. 내가 헷갈리던 부분들 다 술술 말해주심. 조교님 실습설명도 짱이야 하튼 짱임
오늘은 RNN을 배워보자 이전에 배웠던 내용 복습 느낌이라 좋았다. 실습했던 내용과 함께 dimension에 익숙해지는 시간을 가지려고 한다.
RNN
매 순간 동일한 weight 행렬을 이용해 재귀적으로 학습한다.
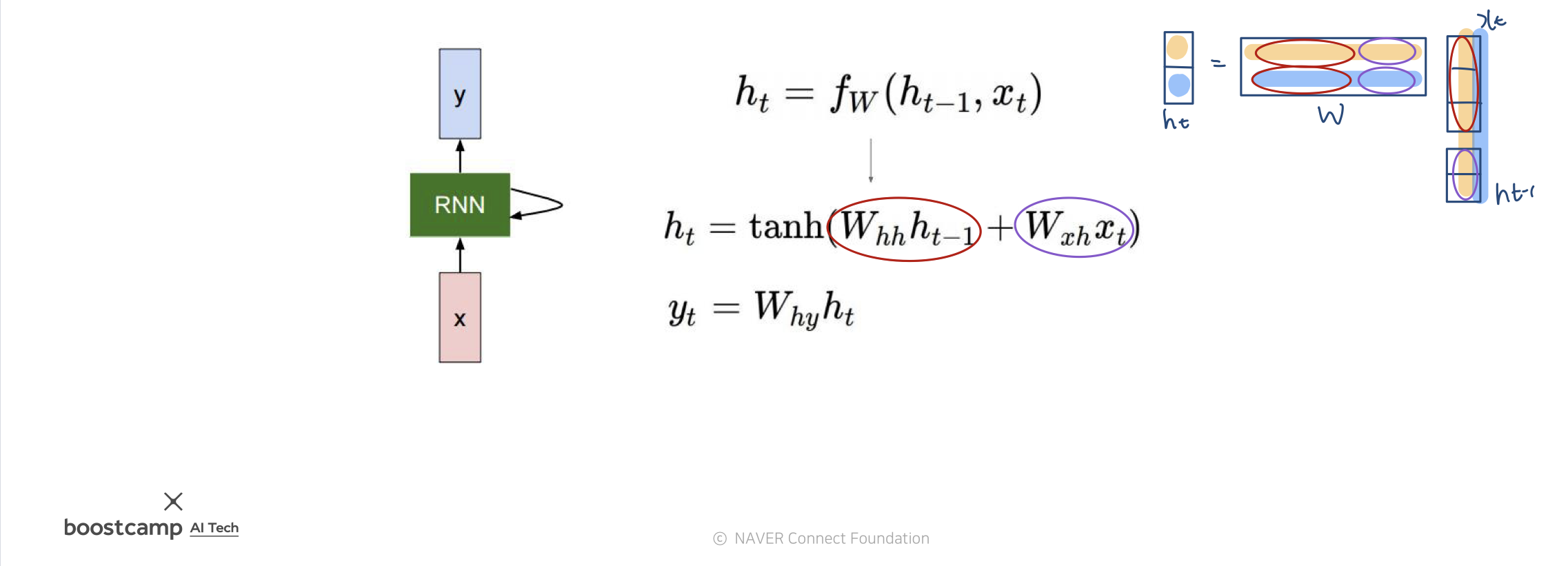
이 한페이지면 충분한 설명이 될 듯 싶다.
행렬들을 이어붙혀서 연산하는 모양새는 오른쪽 그림을 참고하면 된다. 그럼 여기서 구현 코드를 살펴보자.
아 우선, 문장 길이가 다를텐데라는 생각에 도대체가 input의 형태가 그려지지가 않아서 어제 헷갈려서 혼났었다..근데 padding하면 되더라 에궁
우선 이번 실습은 모든 데이터를 하나의 배치로 사용한다.
먼저 한번에 정리하고 가자.
vocab_size = 100
batch size B = 10
maximum sequence length L = 20
embedding_size = 256
batch_emb = (10, 20, 256)
hidden_size = 512
h_0 = (1, 10, 512)
hidden_stated = (20, 10, 512)
h_n = (1, 10, 512)
아래부터는 자세한 설명이다.
우선 기존에 주어졌던 데이터는

이러한데, 뒤에 padding을 붙혀서 (10,20)의 데이터가 완성된다.
단어의 갯수 즉 dict의 key의 갯수는 현재 100이다
이 데이터가 하나의 배치로 쓰인다.
그렇다면 batch size는 10이고 maximum sequence length는 20이다.
단어들을 우선 임베딩 해주어야겠지? embedding dimension은 256으로 지정하였다. 이 숫자는 the size of each embedding vector를 의미한다.
이제 본격적으로 dimension 변화를 살펴볼거다
hidden size는 512, layer는 일단 한개만, 방향은 단방향만 하고 RNN을 돌릴 때!

input_size는 우리가 설정한 embedding vetor의 사이즈이다. 당연하다 벡터로 바뀐 단어들을 input으로 넣어주는 거니까.
hidden_size 또한 사용자 설정인데 일단 512로 설정해두었다.
이제 hidden state 들의 weight를 학습할거다! 우선 0으로 초기화시킬건데 dimension은 아래와 같다.
h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size))
👆즉 (1, 10, 512) 이다!
채널은 layer와 방향의 곱인데, layer별로 오른쪽방향 왼쪽방향 각각 정보를 저장해야해서 그렇다.
hidden_states, h_n = rnn(batch_emb.transpose(0, 1), h_0)
👆rnn에 batch data를 넣으면 hidden_states (각 time step에 해당하는 hidden state들의 묶음), h_n(모든 sequence를 거치고 나온 마지막 hidden state)가 output으로 나온다.
transpose를 하는 이유는 (length, batchz_size, embedding_size)로 들어가야 하기 때문이다
hiddenn_states는 묶음인데, 왜 앞에가 L인지 이해안감..
h_n은 마지막으로 나올 weight이기 때문에 들어갔던 size와 동일할테니 (1, 10, 512)이다
이제 우리는 output h_n을 얻었다. 사이즈는 (1, 10, 512)이다
text classification task
이 최종 output인 h_n을 가지고 classification을 할 수 있는데,

👆clasficication_layer는 (512, 2)로 들어간다. input sample의 사이즈와 output sample의 사이즈이다.
squeeze로 앞의 1은 떼어버리고 (10,512)의 input이 (10,2)로 탈바꿈 되어서 결과가 나온다!
token-level task

hidden_state를 활용하여 token-level task를 수행할 수도 있다.
매번 출력이 나오지 않는가 이걸 entity_layer에 넣어주면 (20, 10, 512) 가 (20, 10, 5) 로 바뀐다.
여기서 잠깐! LM(language model)은 이거랑 좀 다르게 이뤄진다. 얘는 입력 하나하나에 대한 품사를 나타내주는건데
LM은 이전 아웃풋을 다음 인풋으로 넣고 그걸로 또 아웃풋이 나오면 인풋으로 쓰고..재귀적으로 사용하는거다. 그래서 LM은 다르게 해야하는데 그건 밑에서 GRU할 때 보여주겠음!
PackedSequence
padding한 친구들을 정렬해주어서 0이 너무 많아질 때 생기는 문제점을 방지한거다.
코드를 뚝딱뚝ㄸ가 하셨는데 잘 이해가 안간다. 찾아봐야지
RNN의 여러 타입들

한 페이지에 다 요약해봤다 간단!
Character-level language model
h가 들어오면 e를 output으로
e가 들어오면 l을 output으로
l이 들어오면 l을 output으로
l이 들어오면 o를 output으로
이렇게 many to many 형태의 모델이다.
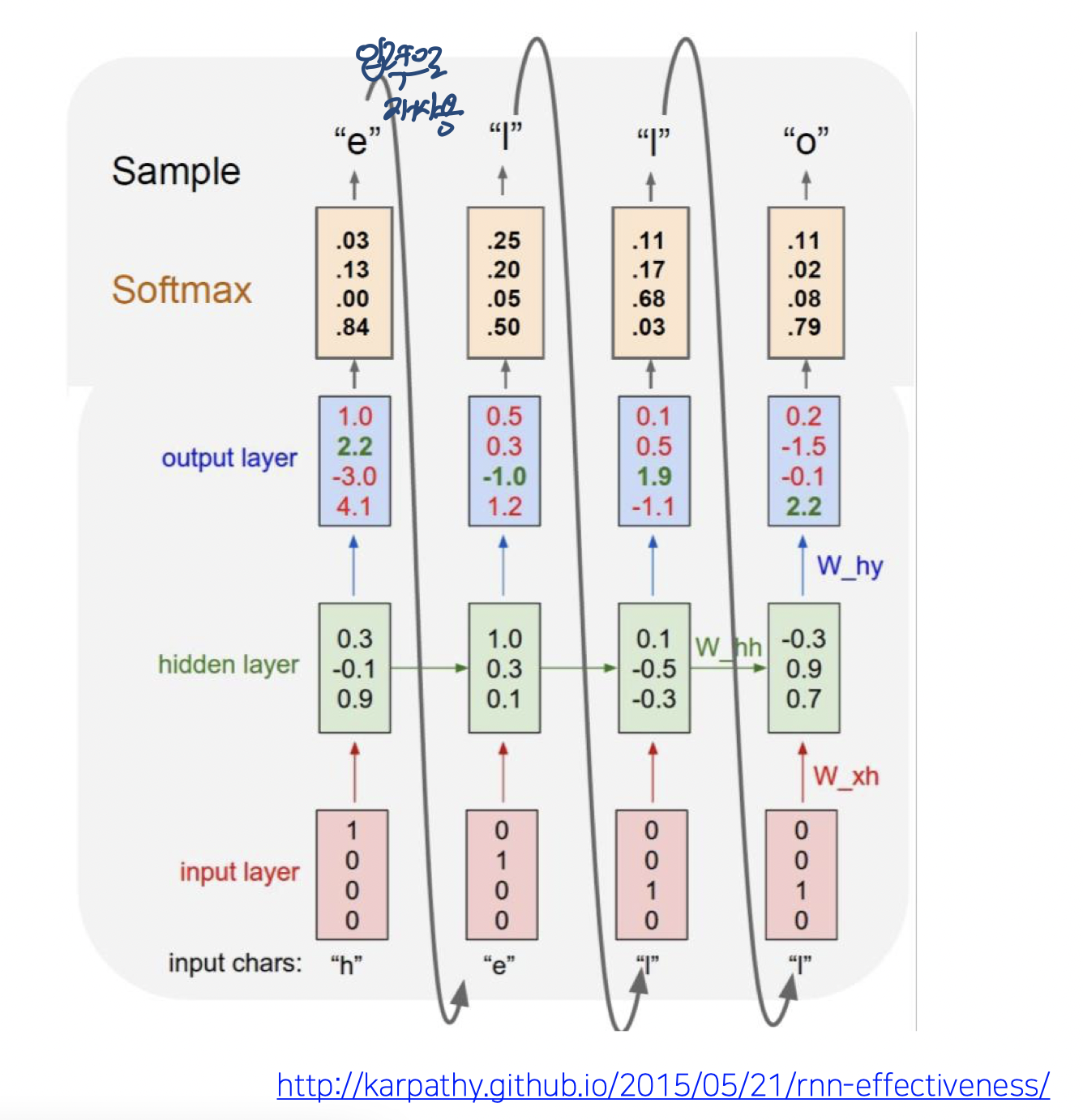
한페이지로 요약되니 넘기고!
이런식으로 학습을 하면 글을 쓸수도 있고 코드를 짤 수도 있다. 논문을 쓸 수도 있다.
Backpropagation through time BPTT
이 모델이 output 다 구하고 loss 쫙 구하고 backpropagation하고 메모리가 참 많이 필요하다. 그래서 잘라서 진행해주는거다.
문제점
매번 weight가 동일해서 등비수열처럼 되버린다. 너무 커지거나 너무 작아져서 gradient vanishing/exploding 문제가 나타난다.
이에 대한 해결책으로 LSTM과 GRU가 있는건데 이건 이전에 정리한 적이 있으니 패스하고 코드를 살펴보자.
LSTM
기존 RNN과 다른 점은 h_0 뿐만 아니라 c_0도 초기화해서 input으로 넣어준다는 점이다.
그 외에는 진짜 넘 똑같다.....
GRU
얘는 심지어 c도 없어서 RNN과 동일하게 사용가능하다. 여기서 이제 LM을 할건데

보면 첫 단어만 input으로 받는걸 볼 수 있다.
여기서 잠깐 teacher forcing을 짚고 넘어가자면, 처음엔 당연히 제대로된 output이 안나올텐데 그걸 계속 다음 레벨의 input으로 사용하면 학습이 힘들 것이다. 그래서 처음엔 input을 인위적으로 실제 정답을 넣어주면서 학습을 시작하는거다. 마치 이전 레벨의 output이 정답이었던것 마냥 하는거지.
이번 실습에서는 teacher forcing을 하진 않고 진행한다! 구냥 저스트 설명이었다구~

for문을 돌면서 output을 계속 input으로 넣어주는건데, 매번 정답일 확률이 가장 큰 애를 뽑아서 output으로 결정해주며 학습을 한다!!
마지막으로 여태 layer 하나만, 단방향으로만 했었는데 2개 이상의 layer와 양방향으로 진행할 수도 있다. 그러면 h_0의 dimension이 바뀌는데 (num_layers * num_dirs, B, d_h) 이었기 때문에 맨 앞이 바뀌는거다.
또 다른 차이점은 output의 dimension인데, 순방향과 역방향의 hidden 을 concat해서 2배가 된다!
즉 hidden state는 (20, 10, 1024)가 된다규
휴 이렇게 끝이 났다 드뎌잔다 ㅃㅃ