[18일차] 벌써...18일차..?
피곤해서 그렇지 내용은 진짜 재밌다. 단지 하루가 48시간이기만 하면 참 좋겠다.
오늘은 sequence to sequence에 대해서 자세히 다뤄본다. 어텐션은 지난번에 배웠었으니 간략하게 설명하고자한다.
Seq2Seq with Attention
문장을 넣어서 문장을 받고싶어하는 모델이다.
기본적으로 encoder와 decoder로 이루어져 있는데,
encoder에서는 input에 대한 hidden state vector를 계산하고,
해당 벡터를 decoder에 넣어서 이 벡터로 지지고 볶으면서 원하는 출력을 내보내고자 하는 것이다.

저기 가운데 thought vector 부분에서 encoder의 최종 hidden state vetor가 decoder의 input으로 들어가고 끝이다.
어제 코드에서도 봤듯이 hidden state vetor가 sentence_max_length 크기로 channel이 생기는데 결과적으로 마지막엔 다 줄여서 (1,n,n)으로 나오지 않았남
이렇듯 마지막 정보는 이전 hidden state의 압축 버전이다. 정보들이 소실될 가능성이 있다는 거다.
그리고 아무리 LSTM이어도 앞 쪽 정보의 소실 가능성은 여전히 존재한다.
이 문제점을 해결하기 위한게 Attention이다. attention은 중간 중간의 hidden vector를 버리지 않는다. 정이 많다.
대신에 최종벡터, 그러니까 decoder의 input 으로 들어온 벡터와 매 time step의 hidden vecotr를 내적하는 방식으로 사용해준다.(내적 말고도 다른 많은 방법이 있는데 그건 뒤에서 다루도록 하자)

그림과 함께 살펴보자면,
빨간색은 매 time step의 hidden vector, 초록색은 decoder의 input 으로 들어온 벡터
저 둘을 내적하면 스칼라 값이 나오는데, 이게 빨간색 벡터들에게 줄 가중치이다!
가중치를 줘서 계산하고 나오는 벡터가 최종 attention output! 맨 꼭데기의 저 친구와 초록색친구를 이용해서 다음 단어 예측을 수행한다.
이제 나머지는 기존 RNN과 동일하게 학습을 지속한다.
backpropagation을 진행할 때에도 기존에는 너~무 거쳐야할 관문이 많았다. 이를 테면
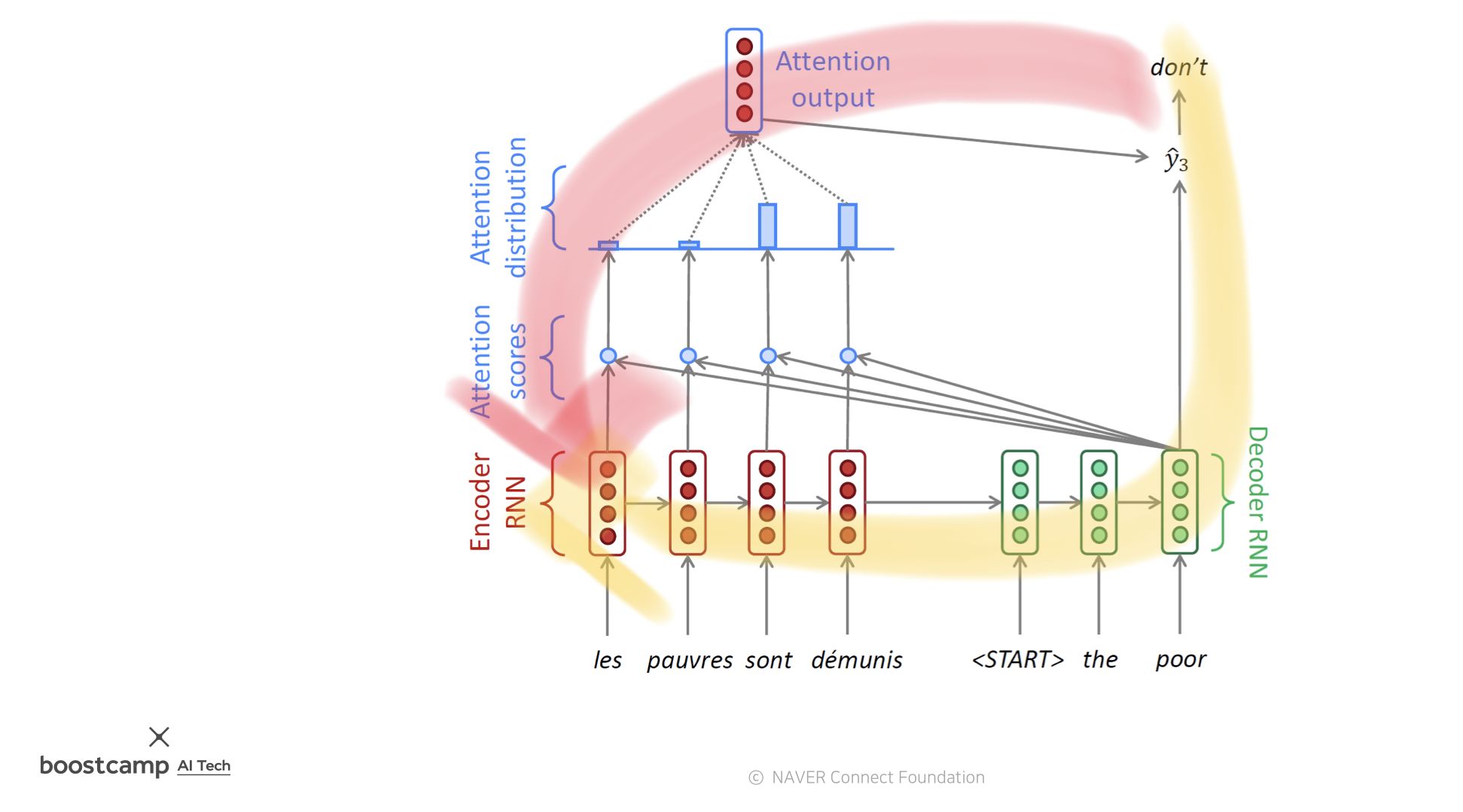
원래는 노란길로 했어야하는걸 빨간 지름길이 생겨서 아주 vanishing gradient 문제를 해결할 수 있게 되었다.